
將生成式 AI 模型擴展到數十億或數萬億個參數需要超出傳統 CPU 能力的專用硬件。圖形處理單元(GPU)仍然是人工智能加速的主導解決方案,一個新的競爭者已經出現:語言處理單元(邏輯處理單元)。
GPU因其并行處理能力而聞名,而 LPU(例如 Groq 開發的 LPU)則旨在解決自然語言處理 (NLP) 任務的順序性,這是構建 AI 應用程序的基本組成部分。在這篇文章中,我們將考慮深度學習工作負載中的 GPU 和 LPU 之間的主要區別,并研究它們的架構、優勢和性能。

GPU 的架構
我們之前討論過特定 GPU 的架構,例如NVIDIA 系列,這將是對 GPU 構成的更一般的概述。
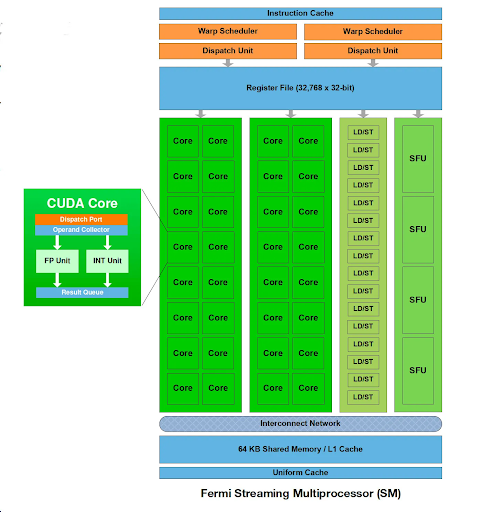
GPU 的核心是計算單元(也稱為執行單元),其中包含多個處理單元(在 NVIDIA 術語中稱為流處理器或 CUDA 核心),以及共享內存和控制邏輯。在某些架構中,尤其是那些為圖形渲染而設計的架構中,還可能存在其他組件,例如光柵引擎和紋理處理集群 (TPC)。
A計算單元由多個較小的處理單元組成,可以同時管理和執行多個線程。它包括自己的寄存器、共享內存和調度單元。每個計算單元并行操作多個處理單元,協調它們的工作以高效處理復雜任務,每個處理單元執行基本算術和邏輯運算的單獨指令。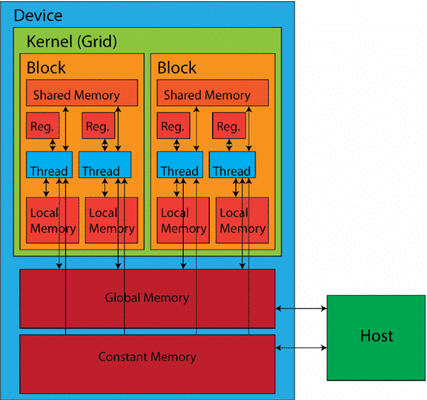
處理單元和指令集架構 (ISA)
計算單元中的每個處理單元都旨在執行由 GPU 定義的一組特定指令指令集架構ISA 決定了處理單元可以執行的操作類型(算術、邏輯等)以及這些指令的格式和編碼。
ISA 是軟件之間的接口(例如,通用計算架構或者OpenCLGPU 包括代碼和硬件(處理單元)。當為 GPU 編譯或解釋程序時,它會被翻譯成一系列符合 GPU 特定 ISA 的指令。然后,處理單元執行這些指令,最終執行所需的計算。
不同的 GPU 架構可能具有不同的 ISA,這會影響其在特定工作負載下的性能和功能。某些 GPU 為特定任務(例如圖形渲染或機器學習)提供專用 ISA,以優化這些用例的性能。
雖然處理單元可以處理通用計算,但許多 GPU 還包含專門的單元來進一步加速特定的工作負載。例如,
雙精度單位(DPU)處理科學計算應用的高精度浮點計算。同時,張量核心(NVIDIA)或專為加速矩陣乘法設計的矩陣核心(AMD)現在是計算單元的組成部分。
GPU 使用多層內存層次平衡速度和容量。最靠近處理核心的是小型片上寄存器,用于臨時存儲經常訪問的數據和指令。這種寄存器文件提供最快的訪問時間,但容量有限。
層次結構中的下一個是共享內存,這是一種快速、低延遲的內存空間,可在計算單元集群內的處理單元之間共享。共享內存有助于在計算過程中進行數據交換,從而提高受益于線程塊內數據重用的任務的性能。
全局內存作為主內存池適用于片上存儲器無法容納的較大數據集和程序指令。全局存儲器比寄存器或共享存儲器提供更大的容量,但訪問時間較慢。
GPU 內的通信網絡
處理單元、內存和其他組件之間的高效通信對于實現最佳 GPU 性能至關重要。為實現此目的,GPU 采用了各種互連技術和拓撲。以下是它們的分類及其工作原理:
1、高帶寬互連:
基于總線的互連:基于總線的互連是許多 GPU 中常用的方法,它為組件之間的數據傳輸提供了共享路徑。雖然實現起來比較簡單,但在流量大的情況下,由于多個組件爭奪總線訪問權限,因此它們可能會成為瓶頸。
片上網絡 (NoC) 互連:一些高性能 GPU 采用NoC 互連,提供更具可擴展性和靈活性的解決方案。NoC 由多個互連的路由器組成,這些路由器在不同組件之間路由數據包,與傳統的基于總線的系統相比,可提供更高的帶寬和更低的延遲。
點對點 (P2P) 互連: P2P 互連支持特定組件(例如處理單元和內存組)之間的直接通信。P2P 鏈路無需共享公共總線,因此可以顯著減少關鍵數據交換的延遲。
2、互連拓撲:
交叉開關:此拓撲允許任何計算單元與任何內存模塊通信。它提供了靈活性,但當多個計算單元需要同時訪問同一個內存模塊時,可能會成為瓶頸。
網狀網絡:網狀網絡拓撲結構中,每個計算單元都以網格狀結構與其相鄰單元相連。這減少了爭用并實現了更高效的數據傳輸,尤其適用于本地化通信模式。
環形總線:在此,計算單元和內存模塊以循環方式連接。這樣數據就可以單向流動,與總線相比,可以減少爭用。雖然廣播效率不如其他拓撲,但它仍然可以使某些通信模式受益。
除了片上互連之外,GPU 還必須與主機系統(CPU 和主內存)通信。這通常通過 PCI Express (PCIe) 總線完成,這是一種高速接口,允許 GPU 與系統其余部分之間傳輸數據。
通過結合不同的互連技術和拓撲,GPU 可以優化各個組件之間的數據流和通信,從而實現跨各種工作負載的高性能。
為了最大限度地利用其處理資源,GPU 使用了兩種關鍵技術:多線程和流水線。GPU 通常采用同步多線程(SMT),允許單個計算單元同時執行來自相同或不同程序的多個線程,從而能夠更好地利用資源,即使任務具有一些固有的串行方面。
GPU 支持兩種形式的并行性:線程級并行(TLP)和數據級并行(DLP)。TLP 涉及同時執行多個線程,通常使用單指令,多線程(SIMT)模型。而 DLP 則使用矢量指令在單個線程內處理多個數據元素。
流水線技術通過將復雜任務分解為更小的階段來進一步提高效率。然后可以在計算單元內的不同處理單元上同時處理這些階段,從而減少總體延遲。GPU 通常采用深度流水線架構,其中指令被分解為許多小階段。流水線技術不僅在處理單元本身內實現,而且在內存訪問和互連中實現。
眾多流處理器、用于特定工作負載的專用單元、多層內存層次以及高效互連的組合,使得 GPU 能夠同時處理大量數據。
要將最新的 NVIDIA GPU 用于您的 AI 和 HPC 項目,聯系我們在捷智算平臺。我們有NVIDIA H100和別的預留 GPU和需求。聯系現在就開始!
LPU的架構
LPU 是市場上的新產品,目前知名度較低,但正如 Groq 所展示的那樣,它們非常強大。LPU 旨在滿足自然語言處理 (NLP) 工作負載的獨特計算需求。我們將重點討論 Groq 的 LPU。
Groq LPU包含一個張量流處理器(TSP)架構。此設計針對順序處理進行了優化,與 NLP 工作負載的性質完美契合。與可能面臨困境的 GPU 架構。由于NLP任務的內存訪問模式不規則,TSP擅長處理數據的順序流,從而能夠更快、更高效地處理語言模型。
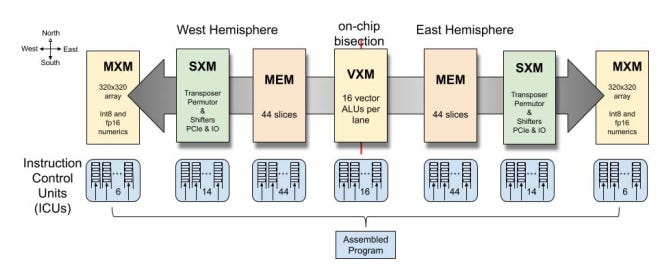
來源:Groq LPU 底層架構
LPU 的架構還解決了大規模 NLP 模型中經常遇到的兩個關鍵瓶頸:計算密度和內存帶寬。通過精心管理計算資源并優化內存訪問模式,LPU 可確保有效平衡處理能力和數據可用性,從而顯著提高 NLP 任務的性能。
LPU 尤其擅長推理任務,其中使用預先訓練的語言模型來分析和生成文本。其高效的數據處理機制和
低延遲設計使其成為聊天機器人、虛擬助手和語言翻譯服務等實時應用的理想選擇。LPU 集成了專用硬件來加速注意力機制等關鍵操作,這對于理解文本數據中的上下文和關系至關重要。
軟件堆棧:
為了彌補 LPU 專用硬件和 NLP 軟件之間的差距,Groq 提供了全面的軟件堆棧。專用編譯器優化和翻譯 NLP 模型和代碼在 LPU 架構上高效運行。該編譯器支持流行的 NLP 框架,如 TensorFlow 和 PyTorch,使開發人員能夠利用他們現有的工作流程和專業知識而無需進行重大修改。
LPU 的運行時環境管理執行期間的內存分配、線程調度和資源利用率。它還為開發人員提供應用程序編程接口 (API) 來與 LPU 硬件交互,從而方便定制和集成到各種 NLP 應用程序中。
內存層次結構:
高效的內存管理對于高性能 NLP 處理至關重要。Groq LPU 采用多層內存層次結構,以確保數據在計算的各個階段都隨時可用。最靠近處理單元的是標量和矢量寄存器,它們為頻繁訪問的數據(如中間結果和模型參數)提供快速的片上存儲。
LPU 使用更大、更慢的二級 (L2) 緩存來存儲不常訪問的數據。此緩存是寄存器和主內存之間的中介,減少了從較慢的主內存中獲取數據的需要。
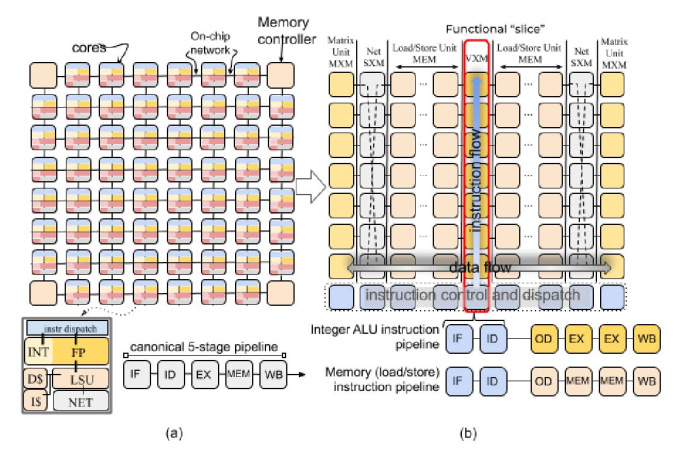
來源:Groq LPU 底層架構
大容量數據的主要存儲是主存儲器,用于存儲預訓練模型以及輸入和輸出數據。在主存儲器中,分配了專用的模型存儲,以確保高效訪問預訓練模型的參數,這些參數可能非常大。
此外,LPU 還集成了高帶寬片上 SRAM,減少了對較慢外部存儲器的依賴,從而最大限度地減少延遲并最大限度地提高吞吐量。這對于涉及處理大量數據的任務(例如語言建模)尤其有益。
1、互連技術:
這Groq LPU 使用互連技術以促進處理單元和內存之間的高效通信。基于總線的互連可處理一般通信任務,而片上網絡 (NoC) 互連可為要求更高的數據交換提供高帶寬、低延遲通信。點對點 (P2P) 互連可實現特定單元之間的直接通信,從而進一步降低關鍵數據傳輸的延遲。
2、性能優化:
為了最大限度地利用處理資源,LPU 采用了多線程和流水線技術。神經網絡處理集群 (NNPC) 將專為 NLP 工作負載設計的處理單元、內存和互連組合在一起。每個 NNPC 可以同時執行多個線程,從而顯著提高吞吐量并實現線程和數據級并行。
流水線技術將復雜任務分解為多個小階段,允許不同的處理單元同時處理不同的階段,從而進一步提高效率。這可減少總體延遲并確保數據通過 LPU 的連續流動。
性能比較
LPU 和 GPU 具有不同的用例和應用,反映了它們的專門架構和功能。
Groq 的 LPU 被設計為推理引擎對于 NLP 算法來說,因此很難在相同的基準上真正地并排比較這些芯片。Groq 的 LPU 能夠比目前市場上的任何 GPU 更快地加速 AI 模型的推理過程,并且每秒最多可生成五百個推理令牌,這意味著只需幾分鐘就可以寫出一本小說。

GPU 并非專為推理而設計,它們可用于整個 AI 生命周期,包括推理、訓練和部署所有類型的 AI 模型。借助用于 AI 開發的專用核心(如 Tensor Core),GPU 可用于 AI 訓練。GPU 還可用于數據分析、圖像識別和科學模擬。
兩者都可以處理大型數據集,但 LPU 可以包含更多數據,從而加快推理過程。Groq 的 LPU 架構采用高帶寬、低延遲通信和高效的數據處理機制設計,可確保這些 NLP 應用程序順暢高效地運行,從而提供卓越的用戶體驗。
通用并行處理:除了人工智能之外,GPU 還擅長加速涉及大型數據集和并行計算的各種任務,使其成為數據分析、科學模擬和圖像識別中的寶貴工具。
選擇合適的工具
如果您的工作負載高度并行,并且需要跨各種任務實現高計算吞吐量,那么 GPU 可能是更好的選擇。如果您正在處理從開發到部署的整個 AI 流程,那么 GPU 將是您投資的最佳硬件。
但是,如果您主要關注 NLP 應用程序,尤其是涉及大型語言模型和推理任務的應用程序,那么 LPU 的專門架構和優化可以在性能、效率和潛在降低成本方面提供顯著優勢。
您可以在捷智算平臺上以實惠的價格使用最好的 GPU。











