
在為您的組織選擇最佳大型語言模型 (LLM)時,需要考慮許多因素。其中一個重要方面是模型的參數數量;通常,較大的模型往往表現更好。您還可以查看性能基準或推理測試,它們提供性能的量化指標,并允許您比較不同的 LLM。
但是,在選擇了似乎適合您需求的模型后,您可以通過調整超參數進一步定制它。這些設置可以顯著影響 LLM 是否滿足或超出您的期望。

什么是 LLM 超參數?為什么它們很重要?
超參數是影響LLM 訓練過程的設置。與在訓練期間調整的模型參數(或權重)不同,超參數在訓練開始前設置并保持不變。它們控制模型如何從訓練數據中學習,但不會成為最終模型的一部分。因此,您無法確定訓練完成后使用了哪些超參數。
超參數至關重要,因為它們允許您調整模型的行為以更好地滿足您的特定需求。您無需從頭開始創建自定義模型,而是可以通過超參數調整對現有模型進行微調,以實現所需的性能。
探索不同的 LLM 超參數
1. 模型大小
LLM 的大小(指其神經網絡中的層數)是一個主要的超參數。較大的模型通常表現更好,可以處理更復雜的任務,因為它們具有更多的層和權重,使它們能夠學習 token 之間的復雜關系。但是,較大的模型訓練和運行成本更高,需要更多數據,并且速度可能更慢。它們也更容易過度擬合,即模型在訓練數據上表現良好,但在新數據上表現不佳。
較小的模型雖然功能較弱,但可以更有效地完成簡單的任務,并且更容易在功能較弱的硬件上部署。它們需要的訓練資源較少,并且可以通過量化和微調等技術進一步優化。
2. 周期數
一個 epoch 是完整遍歷訓練數據集的一次訓練。epoch 的數量決定了模型處理整個數據集的頻率。更多的 epoch 可以提高模型的理解能力,但如果使用的 epoch 太多,則會導致過度擬合。相反,epoch 太少會導致欠擬合,即模型沒有從數據中學到足夠的知識。
3.學習率
學習率控制模型在訓練過程中響應錯誤的更新速度。較高的學習率會加快訓練速度,但可能會導致不穩定和過度擬合。較低的學習率會增加穩定性并改善泛化能力,但會使訓練速度變慢。通常,使用基于時間的衰減、步長衰減或指數衰減等計劃隨著訓練的進展調整學習率是有益的。
4. 批次大小
批次大小是模型一次處理的訓練示例數量。較大的批次大小可加快訓練速度,但需要更多內存。較小的批次對硬件的要求較低,但可以提高模型從每個數據點學習的徹底程度。
5. 最大輸出代幣
此超參數也稱為最大序列長度,用于設置模型在其輸出中可以生成的最大標記數。標記越多,響應越詳細、越連貫,但計算和內存需求也會增加。標記越少,這些需求就會減少,但可能會導致響應不完整或連貫性降低。
6. 解碼類型
解碼是從模型的內部表示生成模型輸出的過程。主要有兩種類型:貪婪解碼,即在每個步驟中選擇最可能的標記;抽樣解碼,即通過從可能的標記子集中進行選擇來引入隨機性。抽樣可以創建更加多樣化和富有創意的輸出,但會增加無意義響應的風險。
7. Top-k 和 Top-p 采樣
使用抽樣解碼時,top-k 和 top-p 是控制如何選擇 token 的附加超參數。Top-k 抽樣將模型限制為從概率最高的前 k 個 token 中進行選擇。例如,如果將 top-k 設置為 5,則模型將從 5 個最可能的 token 中進行選擇。這有助于確保可變性,同時保持對可能選項的關注。
Top-p 采樣(或核心采樣)根據累積概率動態調整選擇池,確保所選標記構成指定的概率質量(例如 90%)。此方法允許模型根據其概率考慮不同數量的標記,從而平衡隨機性和連貫性。
當然!讓我們來思考一下這句話,“她決定以…開始她的一天”。
現在,讓我們看一下結束這個句子的五種可能的方式,每種方式都以不同的標記開頭:
讀書
慢跑
做早餐
冥想15分鐘
在她的日記里寫道
我們將為每個初始標記分配一個概率,如下所示:
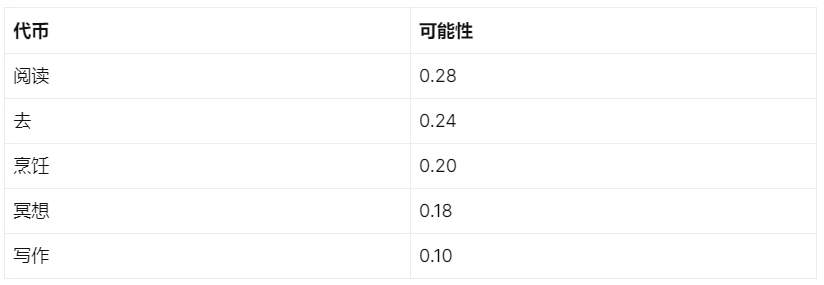
Top-k 采樣
如果我們將 top-k 抽樣值設置為 2,則抽樣子集中只會考慮“reading”和“going”。將其設置為 5 將包含所有選項。
Top-p 抽樣
對于 top-p 抽樣,如果該值設置為 0.6,則會包括“閱讀”和“去”,因為它們的組合概率為 0.52(0.28 + 0.24)。包括“烹飪”將使累積概率為 0.72(0.28 + 0.24 + 0.20),這超過了閾值,因此排除了“烹飪”、“冥想”和“寫作”。
如果兩個采樣值都設置了,則top-k優先,確保所有超出設定閾值的概率都設置為0。
8.溫度
溫度是一個影響可能輸出 token 的范圍和模型“創造力”的參數,類似于 top-k 和 top-p 采樣值。它用 0.0 到 2.0 之間的十進制數表示。溫度為 0.0 會導致貪婪解碼,其中始終選擇概率最高的 token。相反,溫度為 2.0 可以實現最大的創造力。
低溫會放大概率之間的差異,使高概率的標記更有可能被選中,從而產生更可預測和可靠的響應。另一方面,高溫會導致標記概率收斂,使可能性較小的標記有更好的機會被選中,從而增加隨機性和創造性。
9. 停止序列
停止序列提供了一種控制 LLM 響應長度的方法,與最大輸出標記參數一起。停止序列是一個或多個字符的特定字符串,遇到該字符串時會停止模型的輸出。一個常見的例子是句號(句號)。
或者,您可以使用停止標記限制,即定義輸出長度的整數值。例如,將停止標記限制設置為 1 會使生成的輸出停止在一個句子處,而將限制設置為 2 會將響應限制為一個段落。這些控制對于管理推理非常有用,尤其是在預算成為問題時。
10. 頻率和存在懲罰
頻率和存在懲罰是超參數,用于阻止重復并鼓勵模型輸出的多樣性。-2.0 和 2.0 之間的小數表示兩種懲罰。
頻率懲罰降低了最近使用過的 token 的概率,使其不太可能重復出現。這有助于通過防止重復產生更多樣化的輸出。存在懲罰適用于至少出現過一次的 token,其工作原理類似,但與 token 使用頻率成正比。頻率懲罰阻止重復,而存在懲罰鼓勵使用更多種類的 token。
什么是 LLM 超參數調整?
LLM 超參數調整涉及在訓練過程中調整各種超參數,以找到生成最佳輸出的最佳組合。此過程通常涉及大量反復試驗,細致地跟蹤每個超參數應用并記錄結果輸出。手動執行此調整非常耗時,因此需要開發自動化方法來簡化流程。
自動超參數調整最常見的三種方法是隨機搜索、網格搜索和貝葉斯優化:
隨機搜索:此方法從指定的值范圍內隨機選擇并評估超參數組合。該方法簡單高效,能夠探索較大的參數空間。但是,由于其簡單性,它可能找不到最佳組合,并且計算成本高昂。
網格搜索:此方法系統地搜索給定范圍內所有可能的超參數組合。雖然像隨機搜索一樣耗費資源,但它可以確保以更系統的方式找到最佳超參數集。
貝葉斯優化:此方法使用概率模型來預測不同超參數的性能,并根據這些預測選擇最佳超參數。它比網格搜索更有效,可以用更少的資源處理較大的參數空間。但是,它的設置更復雜,并且在識別最佳超參數集方面可能不如網格搜索可靠。
自動超參數調整的優勢
自動超參數調優為機器學習模型開發提供了幾個顯著的優勢。首先,它通過系統地搜索超參數空間節省了時間和精力,從而無需手動反復試驗的方法。這可以發現更優化的超參數配置,從而提高模型性能和準確性。此外,自動調優利用了貝葉斯優化、網格搜索和隨機搜索等復雜算法,可以更有效地探索超參數格局。
這樣可以更快地收斂到最佳設置。此外,自動調整可以輕松集成到現有的機器學習管道中,確保無縫工作流程并通過迭代改進實現持續改進。通過減少對人類專業知識的依賴,它使高級模型調整的訪問變得民主化,即使是那些在機器學習方面經驗有限的人也可以使用它。
結論
超參數調優通常被視為微調的一個子集,但它是一門值得單獨關注的重要學科。通過配置本指南中詳細介紹的各種超參數,并觀察所選 LLM 的響應情況,您可以增強基礎模型的性能,以更好地適應實際應用。
加入捷智算平臺
如果您是 AI 研究員、深度學習專家、機器學習專業人士或大型語言模型愛好者,我們希望聽到您的聲音!加入捷智算平臺將讓您盡早體驗高性價比的算力資源,幫助您實現項目。
不要錯過這個激動人心的機會,徹底改變您開發和部署應用程序的方式。立即使用捷智算云平臺:https://www.supercomputing.net.cn/











