
Stable Diffusion 是一種人工智能模型,可將簡單的文本提示轉換為令人驚嘆的高分辨率圖像,為藝術家、設計師和愛好者開辟了創意可能性。然而,就像所有我們討論過的生成式人工智能模型,Stable Diffusion需要大量的計算資源。
捷智算平臺可訪問 NVIDIA A40 GPU,旨在加速 AI 工作負載。通過將Stable Diffusion與 A40 的高性能功能相結合,您可以生成復雜的藝術品、嘗試各種風格,并在比僅使用 CPU 更短的時間內將您的藝術構想變為現實。
無論您是經驗豐富的 AI 藝術家還是好奇的初學者,本指南都將引導您在捷智算平臺上使用 NVIDIA A40 實現Stable Diffusion。我們將介紹從獲取模型到啟動第一個圖像生成項目的所有內容。
選擇您的型號
第一步是選擇模型。在本指南中,我們將使用Stable AI 的Stable Diffusion模型。該模型及其文檔位于 hugging face 上。
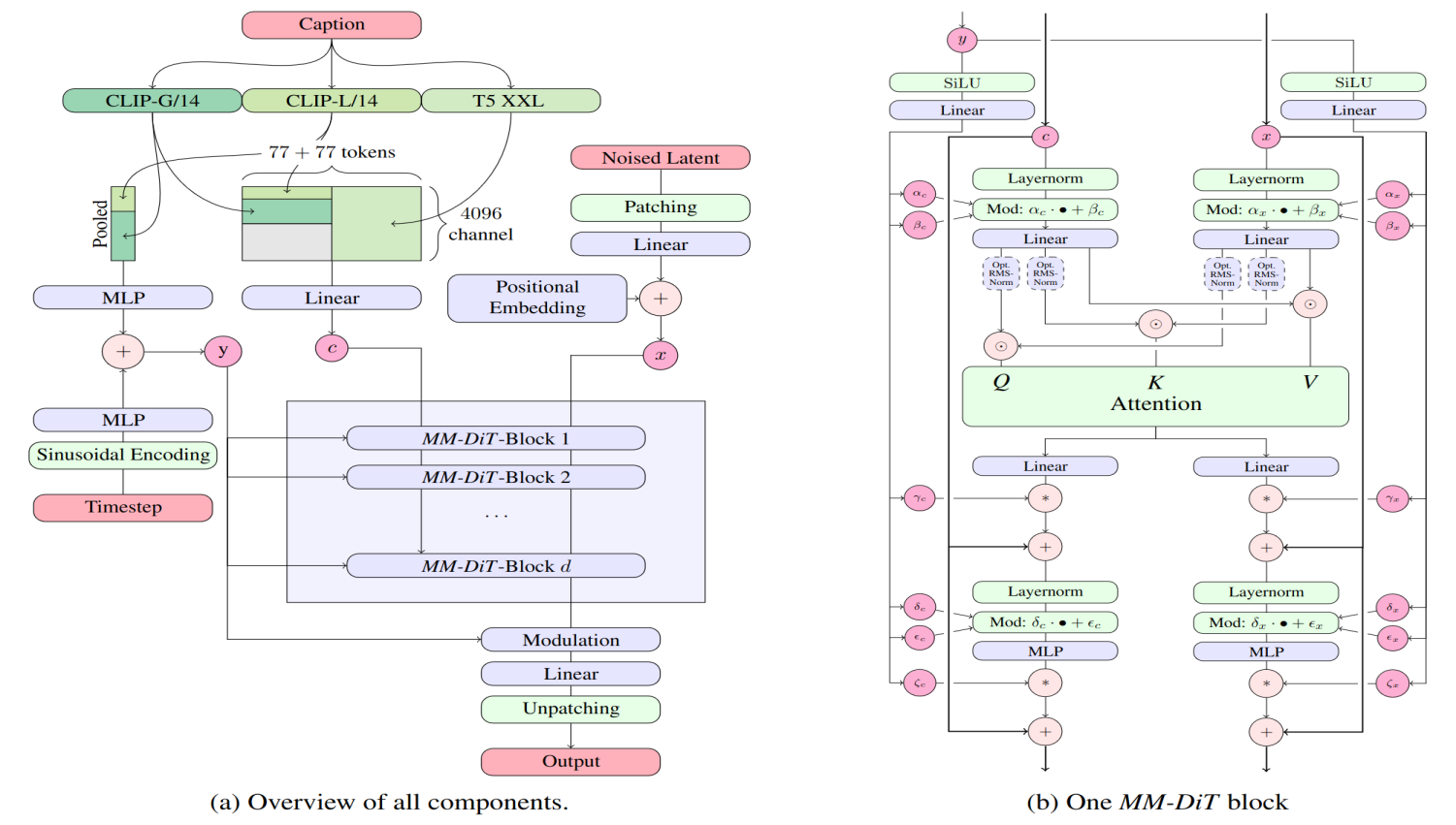 來源:Stability AI
來源:Stability AI
從 hugging face 獲取模型時,您首先必須創建一個帳戶。完成后,您必須生成一個訪問令牌,您將使用該令牌將模型拉入您的 VM。為此,請單擊您的個人資料圖片并導航到“設置”。
單擊“訪問令牌”,然后單擊“創建新令牌”。
選擇此令牌的所有必要權限、您希望它訪問的存儲庫、您希望它訪問的組織等等。完成后,單擊“創建令牌”。復制令牌并將其保存在安全的地方。
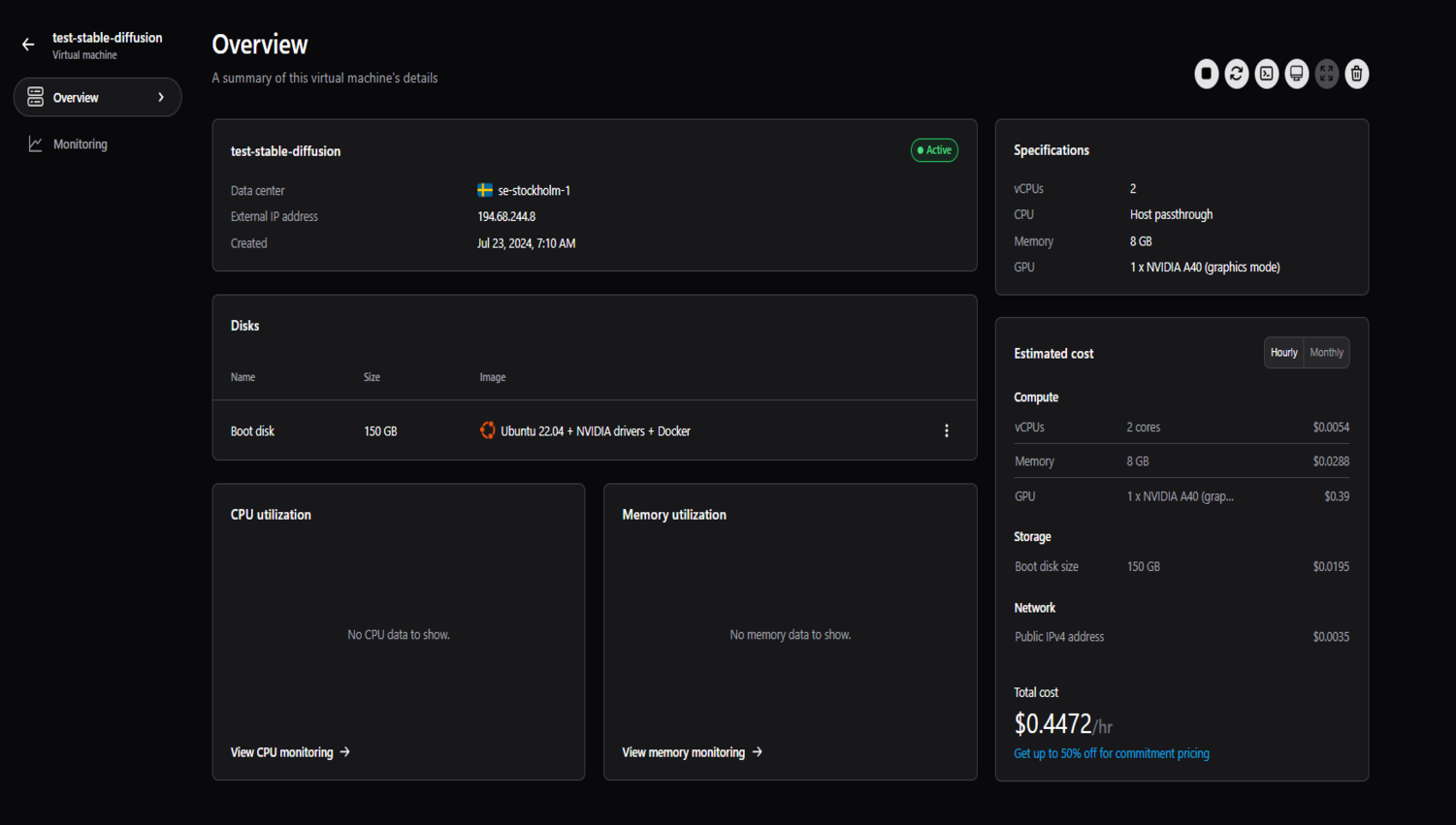
接下來,在捷智算平臺上創建項目并創建虛擬機。我們將使用 NVIDIA A40 以及 2 個 vCPU、8GB 內存和 150GB 啟動盤。
通過 SSH 進入您的虛擬機,然后運行更新和升級命令。
sudo apt update && sudo apt upgrade -y
然后安裝 pip,我們將在安裝其他 Python 庫和框架時使用它,命令如下:
apt install python3-pip
接下來,我們將在機器上安裝虛擬環境。即使您在虛擬機中工作,出于以下原因,最好這樣做:
隔離:虛擬環境隔離了項目的 Python 依賴項,從而避免了可能需要同一庫的不同版本的不同項目之間發生沖突。在沒有虛擬環境的情況下為一個項目安裝庫可能會破壞依賴于不同版本的另一個項目。
可重復性:虛擬環境確保您的項目具有正確運行所需的精確依賴關系,從而更容易與他人共享您的項目或將其部署到生產中,因為您可以確信環境將是相同的。
整潔:虛擬環境使整個系統的 Python 安裝保持整潔。您不會因項目特定的依賴項而弄亂虛擬機的全局庫,從而更輕松地在虛擬機上管理 Python。
即使您在提供一定隔離的云虛擬機中工作,虛擬環境也能對特定于您的項目的依賴項提供更細粒度的控制。
我們將使用venv在本指南中,但您可以使用不同的工具來管理您的虛擬環境,例如conda。由于我們使用的是 Ubuntu 系統,因此我們必須使用以下命令安裝 python3-venv 包。
apt install python3.10-venv
現在,我們將為項目創建一個文件夾并導航到其中。
mkdir stable_diffusion && cd stable_diffusion
我們將使用之前安裝的 venv 在此文件夾中創建虛擬環境。
python3 -m venv venv
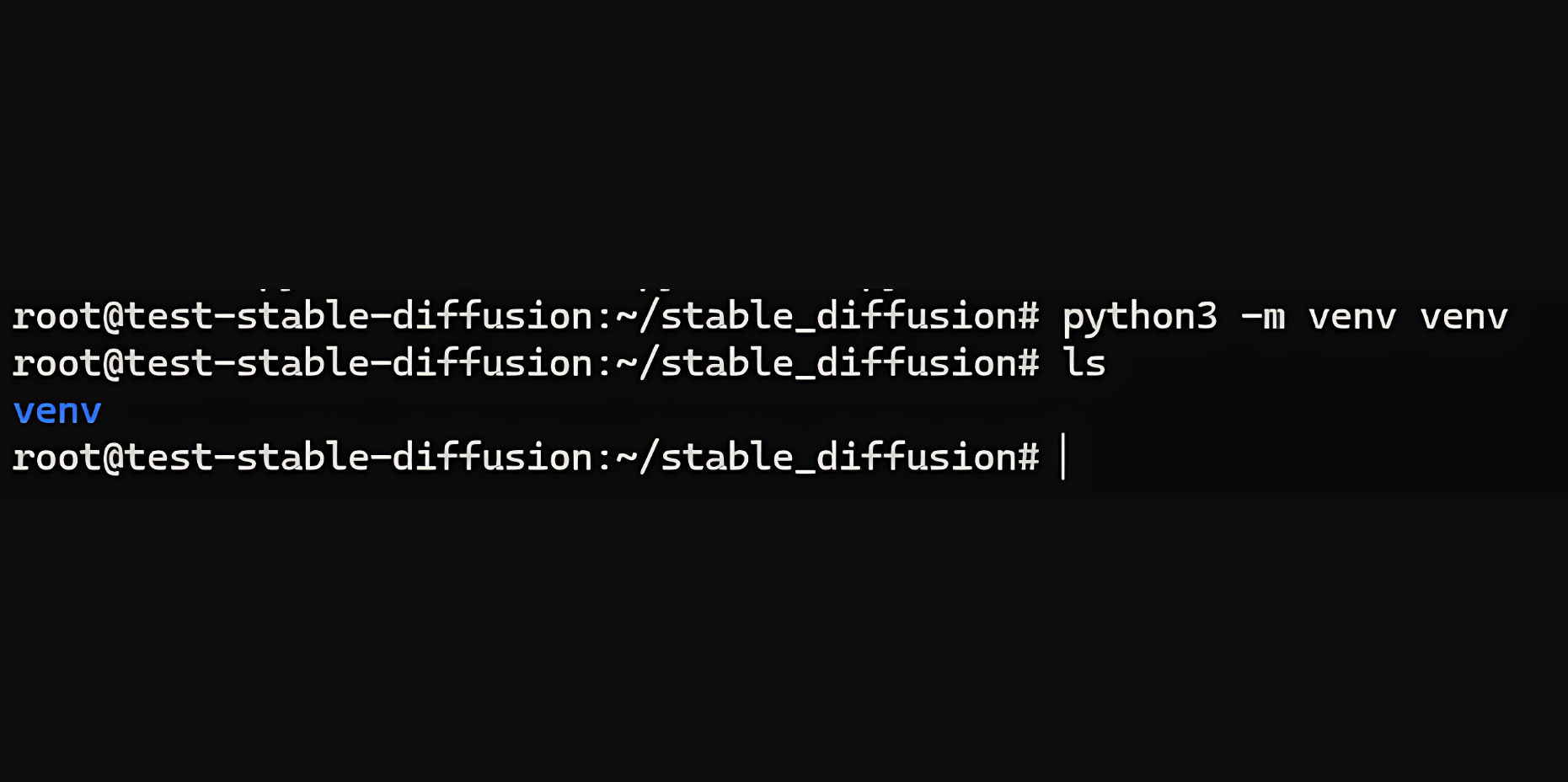
您應該在此目錄中有一個 venv 文件夾,如上圖所示。接下來,使用此命令激活虛擬環境。
source venv/bin/activate
激活虛擬環境后,我們可以安裝所需的庫和依賴項。
pip install torch torchvision torchaudio diffusers huggingface_hub matplotlib accelerate transformers sentencepiece protobuf
這需要一點時間才能運行。完成后,您就可以在捷智算平臺上使用穩定擴散了。
接下來,我們將創建一個腳本來在虛擬機上測試該模型。
首先,我們將創建一個文件夾來保存我們想要用這個模型生成的圖像。
mkdir generated_images
然后,我們開始編寫代碼。
導入您需要的所有模塊。
import os
import torch
from diffusers import DiffusionPipeline
from huggingface_hub import HfFolder, login
from PIL import Image
接下來,我們必須驗證我們的 Hugging Face ID 來提取模型。
# Set your Hugging Face token
token = "your_hugging_face_token"
os.environ["HF_AUTH_TOKEN"] = token
HfFolder.save_token(token)
# Login with your token
login(token=token)
該令牌將是您之前創建的 Hugging Face 令牌。
警告:將 Hugging Face 令牌(或任何密鑰)留在代碼庫中存在安全風險。訪問您代碼的人可能會竊取令牌并用它來生成圖片,甚至訪問您的 Hugging Face 帳戶。
始終使用環境變量安全地存儲令牌、密碼和其他機密,以防止這種情況發生。這樣可以將它們與代碼分開,并使它們更難被意外泄露。
接下來,我們使用Diffusion Pipeline加載模型。
# Load the model using DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
這幾行代碼執行與加載和配置用于圖像生成的擴散模型相關的兩個關鍵操作:
加載模型:
DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers"):此行使用來自擴散器庫的 DiffusionPipeline 類的 from_pretrained 方法。它從 Hugging Face Hub 下載預先訓練的擴散模型。此處加載的具體模型是“stabilityai/stable-diffusion-3-medium-diffusers”,它是 Stable Diffusion 3 模型的中型版本。
將模型移至 GPU:
pipe.to("cuda"):此行將加載的模型管道(管道)移動到啟用 CUDA 的設備,如果可用,則為圖形處理單元 (GPU),在我們的例子中,它是。如上所述,擴散模型的計算成本很高,與在 CPU 上運行相比,GPU 可以顯著加速圖像生成過程。
接下來,我們使用加載的擴散模型(管道)根據提供的文本提示和其他參數生成圖像。
# Generate an image
result = pipe(
"A smiling cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
)
讓我們分解一下每個元素:
result = pipe(...):此行調用 pipe 對象,該對象代表已加載的擴散管道。它要求模型根據括號內提供的參數生成圖像。
“一只貓舉著一塊寫著“你好世界”的牌子”:這個文本提示描述了所需的圖像。模型將使用此信息來指導圖像生成過程。
negative_prompt="":這是一個可選參數,用于指定負面提示。負面提示允許您告訴模型您不希望在圖像中出現什么。在這里,我們使用一個空字符串,表示沒有特定的負面提示。
num_inference_steps=28:此參數控制圖像生成過程中使用的推理步驟數。每個步驟都會根據模型對提示的理解來細化圖像。值越高,圖像質量就越高,但生成圖像的時間也越長。
guide_scale=7.0:此參數控制文本提示對生成圖像的影響。較高的值會增加模型對提示的遵守程度,而較低的值則允許更多的創作自由。
執行此代碼后,result 變量將包含有關生成的圖像的信息,包括實際圖像數據本身。接下來,我們檢索生成的圖像并將其保存到特定位置。
# Get the generated image
image = result.images[0]
# Save the image
image_path = "generated_images/generated_image.png"
image.save(image_path)
具體如下:
1、檢索圖像:
result.images 0:如前所述,result 變量保存有關生成圖像的信息。在這里,我們訪問 result 中的 images 屬性。此屬性可能包含生成的圖像列表(可能用于變體或多次生成運行)。我們使用0來訪問列表中的第一個圖像(假設只有一個生成的圖像)。
2、保存圖像
image_path = "generated_images/generated_image.png":此行定義圖像的保存路徑。它將圖像保存為文件名“generated_image.png”。
image.save(image_path):此行使用圖像對象的 save 方法(我們從 result.images 0中檢索到)。該方法將 image_path 作為參數,指定保存圖像的目標位置。
要運行代碼,請使用 python3 命令。假設文件保存為 app.py,請使用以下命令。
python3 app.py
如果您第一次運行代碼,它將從 Hugging Face 下載模型并生成圖像。
圖像將保存在您的 generated_images 文件夾中。要查看它,您只需使用安全復制 (SCP) 將圖像復制到本地計算機即可。為此,請導航到本地計算機上的命令行并運行此命令。
scp root@external_ip:~/stable_diffusion/generated_images/generated_image.png the/destination/path
注意:將 External_IP 替換為虛擬機的實際 IP 地址。如果您已經為虛擬機設置了命名主機,就像我們一樣,你可以改用這個命令:
scp sdserver:~/stable_diffusion/generated_images/generated_image.png the/destination/path
圖像將被復制到您的計算機中。

當在捷智算平臺上使用 A40 GPU 執行穩定擴散任務時,執行速度與本地機器明顯不同。
import os
import torch
from diffusers import DiffusionPipeline
from huggingface_hub import HfFolder, login
from PIL import Image
import time # Import the time module
# Set your Hugging Face token
token = "your_hugging_face_model"
os.environ["HF_AUTH_TOKEN"] = token
HfFolder.save_token(token)
# Login with your token
login(token=token)
# Start time measurement
start_time = time.time()
# Load the model using DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# Generate an image
result = pipe(
"A cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
)
# Get the generated image
image = result.images[0]
# Save the image
image_path = "generated_images/generated_image.png"
image.save(image_path)
# End time measurement
end_time = time.time()
# Calculate and display execution time
execution_time = end_time - start_time
print(f"Script execution time: {execution_time:.2f} seconds")
下載模型后首次運行時該腳本在 CUDO Compute 上的平均執行時間約為 67 秒。
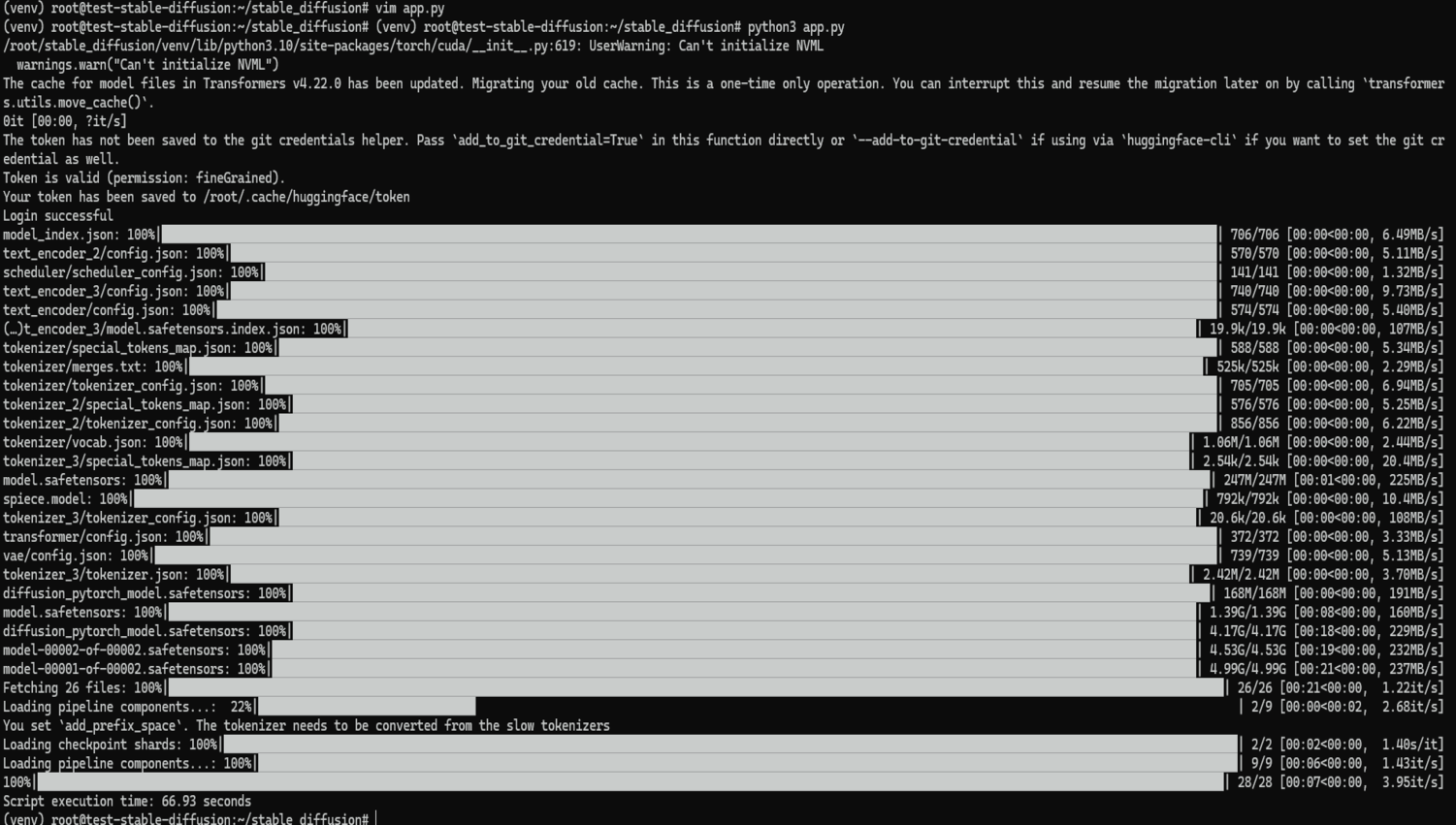

在后續運行中,當模型已緩存時,執行時間平均下降到 41 秒左右。在一臺臺式計算機上運行相同的腳本可能需要數小時。
總結
在本指南中,您已成功學習了如何使用捷智算平臺上的 NVIDIA A40 GPU 和Stable Diffusion模型根據文本提示生成圖像。您已學習了如何:
使用 GPU 在捷智算平臺上設置虛擬機。
創建和管理 Python 虛擬環境以使您的項目保持井然有序。
安裝使用 Stable Diffusion 所需的庫和工具。
通過 Hugging Face 進行身份驗證即可下載模型。
編寫一個 Python 腳本,根據文本提示生成圖像。
將生成的圖像傳輸到本地機器以供查看和共享。
您現在可以嘗試不同的提示和參數,甚至可以在捷智算平臺的基礎設施上探索其他 AI 模型。無論您是藝術家、設計師還是 AI 愛好者,從文本生成圖像的能力都是一個強大的工具,可以增強您的工作流程并激發新的想法。











