
Llama 3.1 帶來新突破
上個月底,Meta推出了Llama 3.1 大型語言模型 (LLM) 系列。它由三個新模型組成——預先訓練和指令調整的文本輸入/文本輸出開源生成式 AI 模型,參數數量分別為 8B、70B 和 405B。
據 Meta 稱,旗艦 405B 版本是“全球最大、功能最強大的公開可用基礎型號”。
開源方法和創新
首席執行官馬克·扎克伯格 (Mark Zuckerberg) 倡導開源方法,并預測它最終將成為行業標準,就像 Linux 之于操作系統一樣。他斷言,與專有的閉源模型相比,開源 AI 模型不僅發展更快,而且具有更大的創新潛力。
Llama 3.1 的發布確實為全球 AI 社區注入了活力,圍繞其潛力展開了大量討論和探索。以下是您需要了解的內容!
先前的目標和最近的成就
今年早些時候,當第一款體型較小的 Llama 3 模型(Llama 2)發布時,Meta表示其近期目標是“讓 Llama 3 具備多語言和多模式能力,擁有更長的語境,并繼續提高推理和編碼等 LLM 功能的整體性能”。
借助 Llama 3.1,它朝著實現這一目標邁出了一大步。LLM 尚未實現多模式,但它確實擁有新的多語言功能(西班牙語、葡萄牙語、意大利語、德語和泰語),以及擴展的工具使用和大幅增加的上下文長度。405B 模型使用超過 16,000 個 NVIDIA H100 GPU 在 15 萬億個標記的海量數據集上進行訓練,比其前代模型復雜得多,功能也強大得多。
性能基準
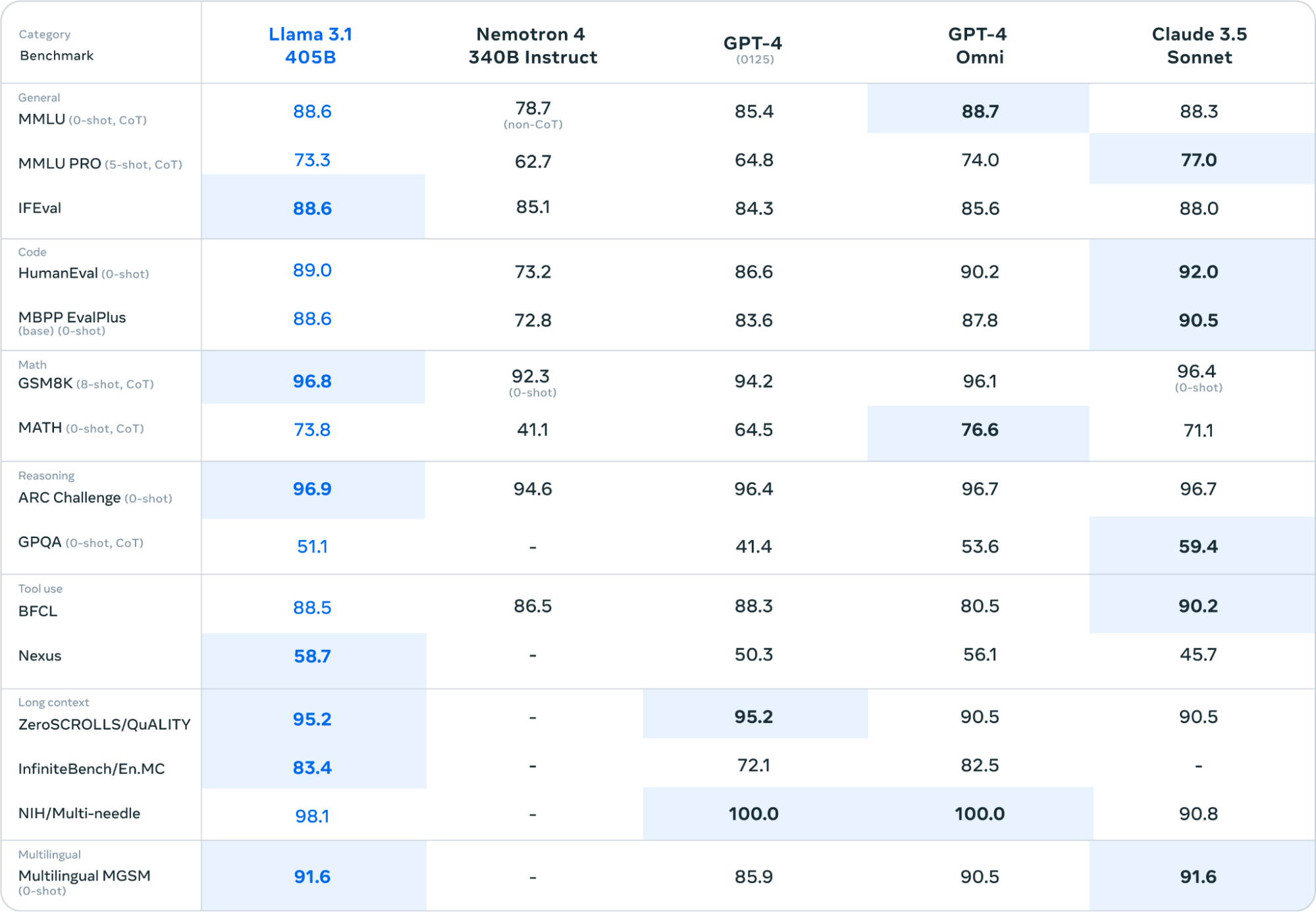
Meta表示,Llama 3.1 405B 在多項基準測試中的表現優于 OpenAI 的 GPT-4 和 GPT-4o 以及 Anthropic 的 Claude 3.5 Sonnet。據報道,在一系列不同的任務中,它與其閉源競爭對手“不相上下”。
以下是 405B 模型與其他常用基準的尖端 LLM 的比較(未包括 Gemini,因為 Meta 難以使用Google的 API 來復制其結果):
模型架構和設計
在介紹 Llama 3.1的博客中,Meta 指出該模型的完整訓練堆棧“得到了顯著優化”。設計選擇優先考慮了模型開發過程的可擴展性和簡單性。
例如,為了最大限度地提高訓練穩定性,Llama 3.1 使用標準的僅解碼器的 Transformer 模型架構,并進行了細微調整,而不是混合專家模型。Meta 還采用了迭代后訓練程序,每輪都使用監督微調和直接偏好優化。結果是每次迭代都會創建出高質量的合成數據,從而增強了每項功能的性能。
405B 模型本身甚至被用來提高較小的 70B 和 8B 模型的訓練后質量。
值得注意的是,為了便于對 405B 規模的模型進行大規模生產推理,Meta 從 16 位 (BF16) 轉換為 8 位 (FP8) 數值。這有效地降低了計算要求并使模型能夠在單個服務器節點內運行。
用戶現在還可以享受更長的上下文窗口。Llama 3.1 模型的上下文長度已從 Llama 3 中的 8,192 個標記擴展到 Llama 3.1 中的 128,000 個標記。這大約是原來的 16 倍!
事實上,擴展的上下文長度現在比 GPT-4 大得多,大約等于企業用戶使用 GPT-4o 獲得的長度,并且與 Claude 3 的 200,000 個標記窗口相當。
最重要的是,高需求時期不會影響訪問,因為 Llama 3.1 可以部署在您自己的硬件或所選的云提供商上。一般來說,也不會有廣泛的使用限制。
使用和構建 Llama 3.1 405B
作為一款如此強大的機型,405B 需要大量的計算資源和開發人員的專業知識才能使用。Meta 明確表示,它希望用戶能夠充分利用它——利用其先進的功能并立即開始構建。以下是一些可能性:
實時和批量推理
監督微調,包括特定領域
LLM-as-a-judge(評估你的模型是否適合你的具體應用)
持續預訓練
檢索增強生成 (RAG)
函數調用
合成數據生成
Meta 生成 AI 副總裁 Ahmad Al-Dahle預測,知識提煉將成為開發人員對 405B 模型的流行用途。也就是說,它可以用作更大的“教師”模型,將其知識和新興能力提煉成更小的“學生”模型,具有更快、更經濟的推理能力。
另一個例子:Al-Dahle 表示,Llama 3.1 可以與搜索引擎 API 集成,以“根據復雜的查詢從互聯網上檢索信息,并連續調用多個工具以完成您的任務。”如果您要求該模型繪制過去五年內售出的房屋數量,“它可以為您檢索[網絡]搜索并生成 Python 代碼并執行它。”還不錯。
Llama 生態系統還為各種用例和高級工作流程提供了交鑰匙指南,供任何人使用。Meta 已與 vLLM、TensorRT 和 PyTorch 等項目合作,從一開始就提供支持,讓用戶更容易上手。
未來趨勢
最終,Llama 3.1 代表了追求開放、可訪問和負責任的 AI 創新的重要飛躍。
在捷智算平臺,我們非常欣賞這些開大規模語言模型的可訪問性,以及周圍社區的合作。我們自己的使命與讓人工智能惠及每個人的理念相一致。
為此,我們很高興能夠在捷智算平臺上提供開源文本生成接口 (TGI) 框架,這樣您就可以提供像 Llama 3.1 這樣的 LLM,并以更實惠的計算成本運行您自己的模型。











