
NVIDIA 的 GH200 Grace Hopper 超級(jí)芯片平臺(tái)顯著推動(dòng)了加速計(jì)算和生成式 AI 的發(fā)展。該平臺(tái)將全球最強(qiáng)大的 GPU 與適應(yīng)性最強(qiáng)的 CPU 結(jié)合在一起。NVIDIA GH200 的可擴(kuò)展設(shè)計(jì)可以管理復(fù)雜的生成式 AI 任務(wù),包括大型語言模型 (LLM)、推薦系統(tǒng)、矢量數(shù)據(jù)庫、圖神經(jīng)網(wǎng)絡(luò) (GNN)等。那么NVIDIA GH200 究竟是什么呢?下面一起了解一下關(guān)于 NVIDIA GH200 你需要知道的一切。
NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛表示:“數(shù)據(jù)中心需要專門的加速計(jì)算平臺(tái)來滿足對(duì)生成式 AI 日益增長的需求。” GH200 的設(shè)計(jì)正是滿足了這一需求。黃仁勛指出:“該 GPU 提供了出色的內(nèi)存技術(shù)和帶寬,可提高吞吐量,允許 GPU 連接和聚合性能而不會(huì)受到影響,并且具有可輕松跨數(shù)據(jù)中心部署的服務(wù)器設(shè)計(jì)。”
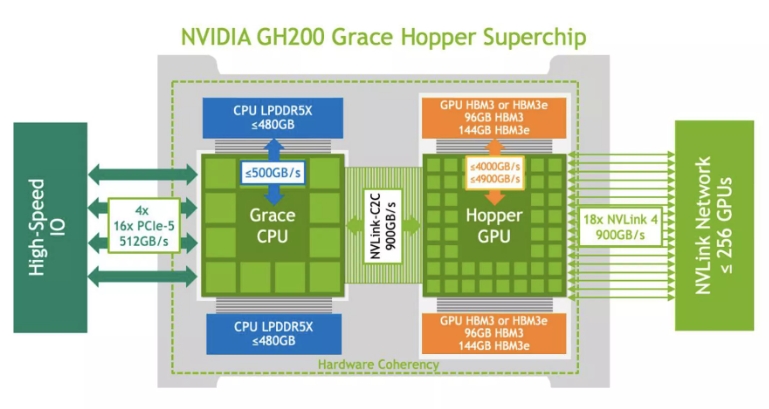
革命性的內(nèi)存和帶寬
GH200 的架構(gòu)樹立了新的高性能計(jì)算 (HPC) 標(biāo)準(zhǔn)。它將先進(jìn)的 Hopper GPU 和靈活的 Grace CPU 集成到單個(gè)超級(jí)芯片中,并通過高速、內(nèi)存一致的NVIDIA NVLink Chip-2-Chip (C2C) 互連進(jìn)行連接。
GH200 Grace Hopper 超級(jí)芯片的核心是 NVLink-C2C 互連,可提供 900GB/s 的雙向 CPU-GPU 帶寬,是傳統(tǒng)加速系統(tǒng)中 PCIe Gen5 連接性能的七倍。此外,互連功耗降低了五倍以上。
NVLink-C2C 允許應(yīng)用程序直接利用 Grace CPU 的高帶寬內(nèi)存來超額使用 GPU 的內(nèi)存。GH200 提供高達(dá) 480GB 的 LPDDR5X CPU 內(nèi)存,當(dāng)與 96GB HBM3 或 144GB HBM3e 結(jié)合使用時(shí),Hopper GPU 可以訪問高達(dá) 624GB 的高速內(nèi)存。
主要特點(diǎn)和初始基準(zhǔn)
NVIDIA Grace CPU 的主要屬性包括:
與標(biāo)準(zhǔn) x86-64 平臺(tái)相比,每瓦性能提高一倍
72 個(gè) Neoverse V2 Armv9 內(nèi)核,配備高達(dá) 480GB 的服務(wù)器級(jí) LPDDR5X 內(nèi)存,具有糾錯(cuò)碼 (ECC)
與八通道 DDR5 設(shè)計(jì)相比,帶寬增加高達(dá) 53%,而每 GB 每秒的功耗僅為八分之一
基于全新 Hopper GPU 架構(gòu)構(gòu)建的 H100 Tensor Core GPU 具有多項(xiàng)創(chuàng)新功能:
通過全新第四代 Tensor Core 實(shí)現(xiàn)極快的矩陣計(jì)算,支持更廣泛的 AI 和 HPC 任務(wù)
與上一代 NVIDIA A100 相比,全新 Transformer Engine 可將 AI 訓(xùn)練速度提高 9 倍,將 AI 推理速度提高 30 倍
通過安全的多實(shí)例 GPU (MIG) 分區(qū),將 GPU 劃分為獨(dú)立且大小合適的實(shí)例,從而提高較小工作負(fù)載的服務(wù)質(zhì)量
總結(jié)來說,GH200 性能強(qiáng)大,但由于發(fā)布時(shí)間不長,綜合基準(zhǔn)測試數(shù)據(jù)仍然有限。不過,讓我們回顧一下一些初步結(jié)果。
初始基準(zhǔn):GH200 與其競爭對(duì)手的比較
經(jīng)過測試的 GH200 系統(tǒng)具有 72 個(gè)內(nèi)核、一塊 Quanta S74G 主板、480GB RAM 和 960GB + 1920GB SAMSUNG SSD 驅(qū)動(dòng)器。這些初步基準(zhǔn)測試強(qiáng)調(diào)了 CPU 性能,但沒有功耗數(shù)據(jù),但它們揭示了值得注意的結(jié)果。
GH200 Grace CPU 在標(biāo)準(zhǔn)HPCG 內(nèi)存帶寬基準(zhǔn)測試中實(shí)現(xiàn)了 41.7 GFLOPS 。
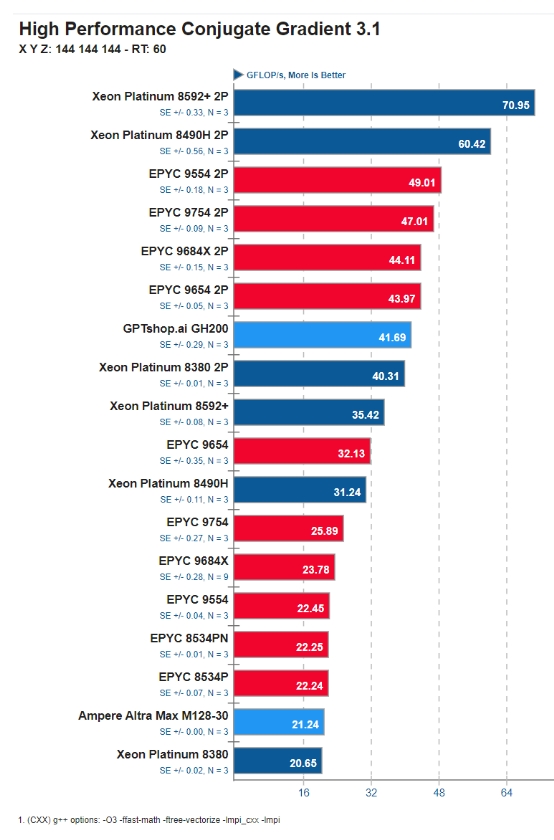
NVIDIA GH200 運(yùn)行 HPCG 基準(zhǔn)測試的結(jié)果
另一個(gè)重要的結(jié)果來自NWChem 基準(zhǔn)測試,GH200 以 1403.5 秒的成績獲得第二名。
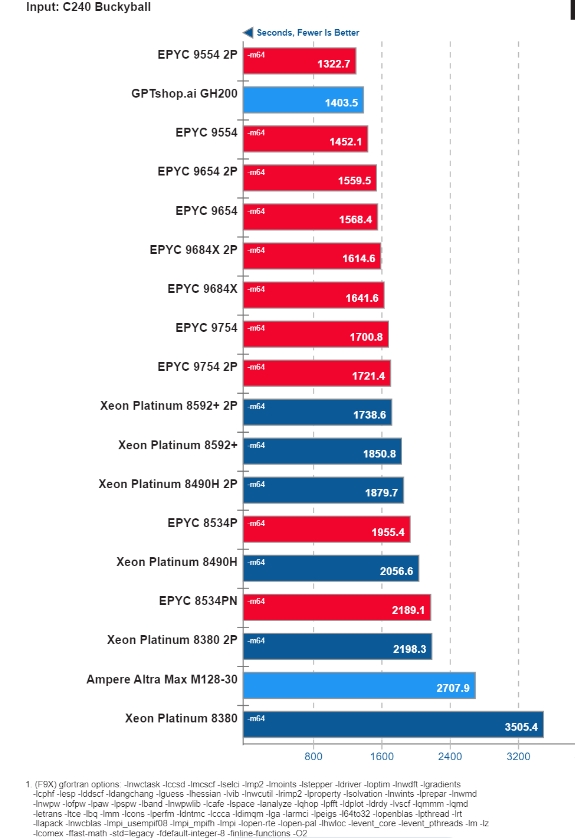
NVIDIA GH200 運(yùn)行 NWChem 基準(zhǔn)測試的結(jié)果
GH200 Grace CPU 的整體性能令人稱贊,在所有基準(zhǔn)測試中都取得了可觀的幾何平均值。
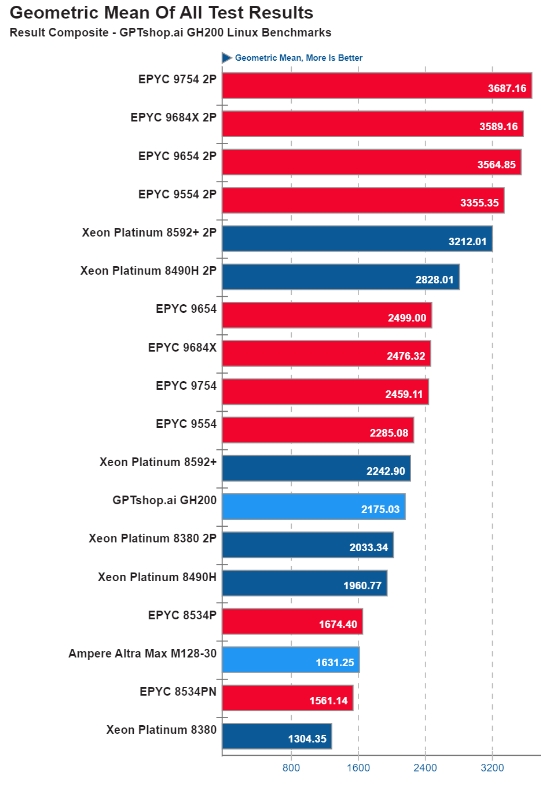
研究員 Simon Butcher進(jìn)行了一系列 GPU 基準(zhǔn)測試,比較了NVIDIA 發(fā)布的PyTorch ResNet50 訓(xùn)練方案的性能。使用 150GB ImageNet 2012 數(shù)據(jù)集,訓(xùn)練運(yùn)行了 90 個(gè) epoch,大約一個(gè)小時(shí)。GH200 在這些測試中表現(xiàn)出色。
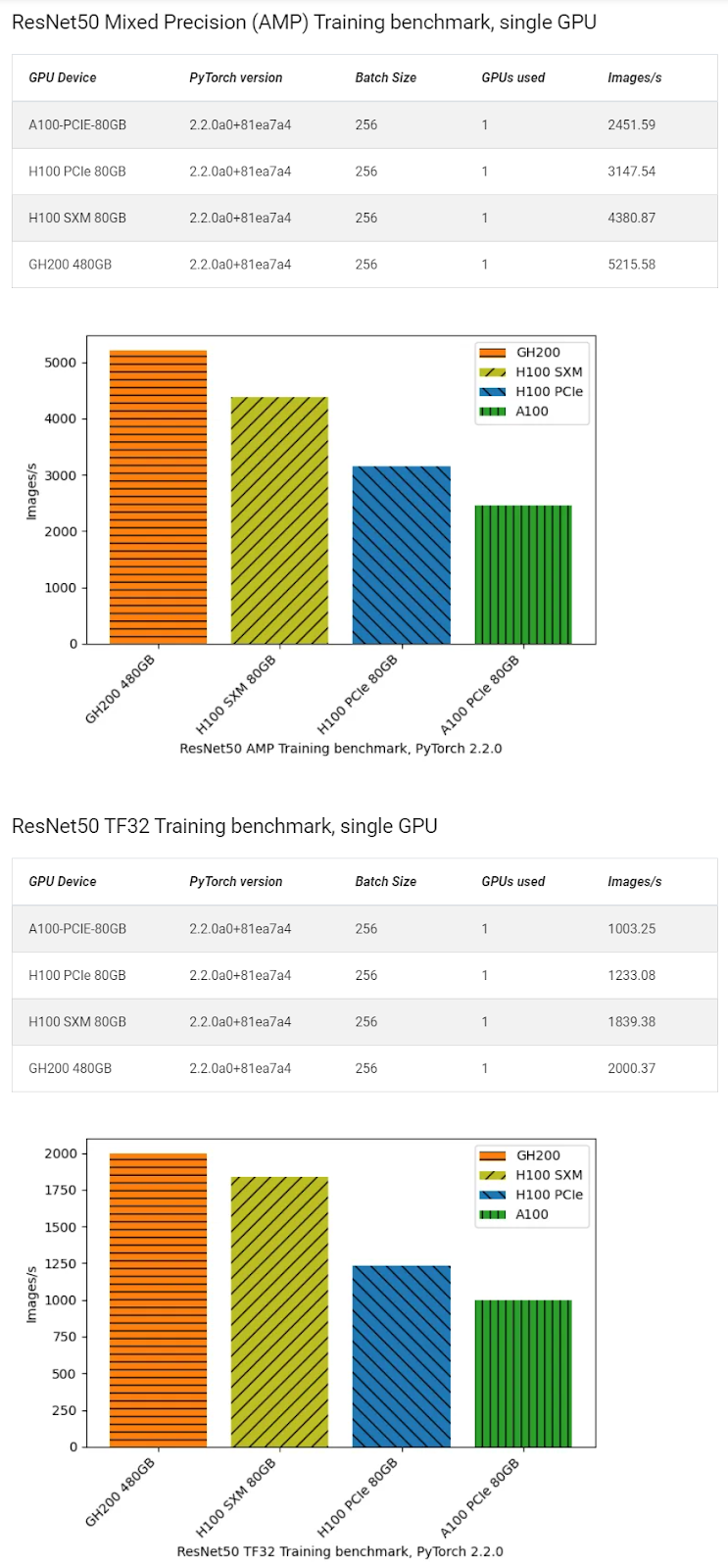
NVIDIA 還發(fā)布了一些可能引起人們興趣的性能比較。
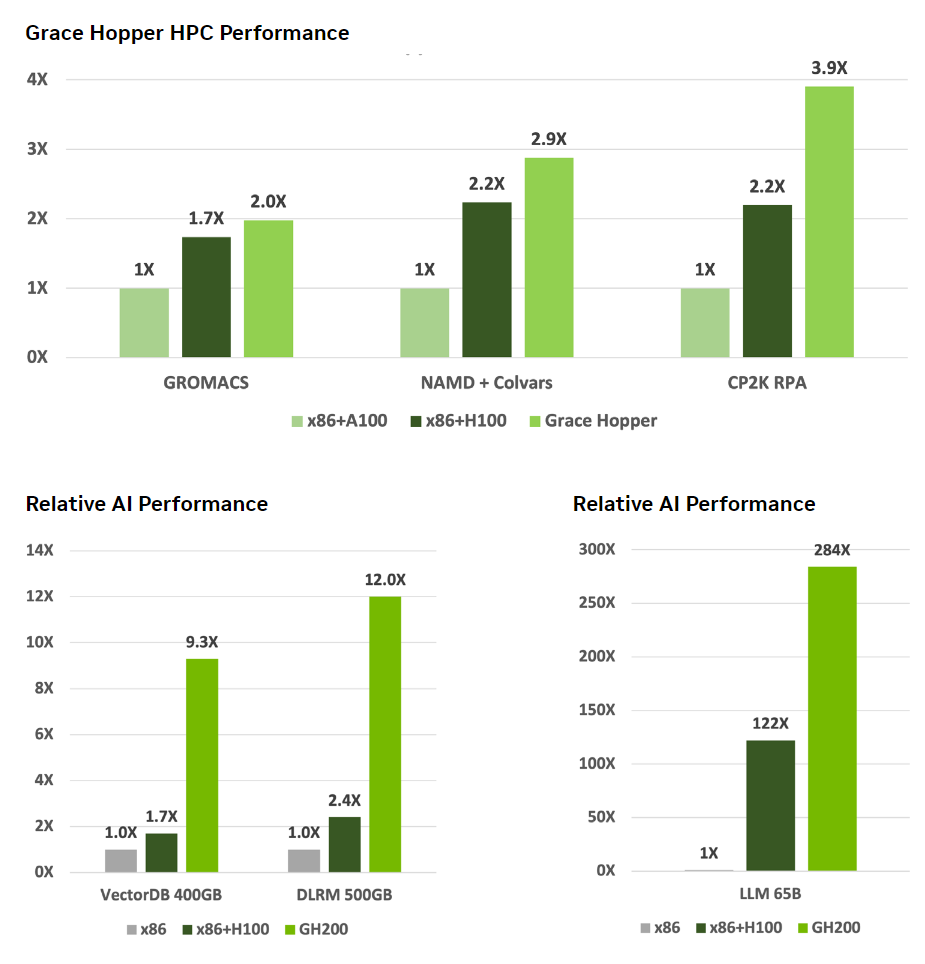
結(jié)論
NVIDIA GH200 Grace Hopper 超級(jí)芯片提供處理 TB 級(jí)數(shù)據(jù)的大規(guī)模 AI 和 HPC 應(yīng)用程序所需的性能。無論您是科學(xué)家、工程師還是管理大型數(shù)據(jù)中心,這款超級(jí)芯片都能滿足需求。
展望未來,NVIDIA 推出了GH200 的繼任者:Grace Blackwell B200,即下一代數(shù)據(jù)中心和 AI GPU。
隨著對(duì) GPU 資源的需求不斷激增,尤其是對(duì)于人工智能和機(jī)器學(xué)習(xí)應(yīng)用的需求,確保這些資源的安全性和易于訪問變得至關(guān)重要。
捷智算平臺(tái)的去中心化架構(gòu)旨在使全球尚未開發(fā)的 GPU 資源的訪問變得民主化,并高度強(qiáng)調(diào)安全性和用戶便利性。讓我們來揭秘捷智算平臺(tái)如何保護(hù)您的 GPU 資源和數(shù)據(jù),并確保去中心化計(jì)算的未來既高效又安全。











